
Что такое OpenCV?
OpenCV — самая популярная библиотека, которая используется для обработки изображений в Python. Он используется для обнаружения и распознавания лиц, идентификации объектов, классификации действий человека в видео, отслеживания движения с помощью камеры и многого другого. Цель этого поста — познакомить вас с основами обработки цифровых изображений с использованием OpenCV в Python. Итак, начнем наше путешествие.
Что такое пиксель и изображение?
Определение изображения очень простое: это двумерное изображение трехмерного мира. Кроме того, цифровое изображение представляет собой числовое представление 2D-изображения в виде конечного набора цифровых значений. Мы называем эти значения пикселями, и все вместе они представляют изображение. По сути, пиксель — это наименьшая единица цифрового изображения (если мы увеличим изображение, мы можем обнаружить их как миниатюрные прямоугольники, расположенные близко друг к другу), которые можно отобразить на экране компьютера. Для более подробного объяснения ознакомьтесь с нашим постом Как получить доступ и редактировать значения пикселей в OpenCV.
Цифровое изображение представляется на вашем компьютере в виде матрицы пикселей. Каждый пиксель хранится как целое число. Если мы имеем дело с изображением в градациях серого, мы используем значения от 0 (черные пиксели) до 255 (белые пиксели). Любое число между этими двумя — это оттенок серого. С другой стороны, цветные изображения представлены тремя матрицами. Каждая из этих матриц представляет один основной цвет, который также называется каналом. Наиболее распространенной цветовой моделью является красный, зеленый, синий (RGB). Эти три цвета смешиваются вместе, чтобы получить широкий спектр цветов. Обратите внимание, что OpenCV загружает цветные изображения в обратном порядке, так что синий канал является первым, зеленый канал — вторым, а красный канал — третьим (BGR). Мы можем видеть порядок каналов на следующей схеме:

Из-за этого у нас могут возникнуть проблемы, поскольку другие пакеты Python (например, matplotlib) используют цветовой формат RGB. Вот почему очень важно знать, как преобразовать изображение из одного формата в другой. Вот один из способов, как это можно сделать необычным способом.
# Necessary imports import cv2 import numpy as np import matplotlib.pyplot as plt # For Google Colab we use the cv2_imshow() function from google.colab.patches import cv2_imshow# We load the image using the cv2.imread() function # Function loads the image in BGR order img = cv2.imread("Benedict.jpg",1) cv2_imshow(img)
Вывод:

Однако, когда мы строим наше изображение с помощью matplotlib из-за того, что он использует порядок цветов RGB, цвета в нашем отображаемом изображении будут обратными.
plt.imshow(img)Вывод:

Теперь у нас есть два изображения. Первый — это наше исходное изображение. Кроме того, мы также создали второй (img1), в котором мы разделили исходное изображение на 3 канала, а затем объединили их вместе в порядке RGB. Далее мы собираемся построить оба изображения, сначала с помощью OpenCV, а затем с помощью matplotlib.
# We can split the our image into 3 three channels
(b, g, r) = cv2.split(img)
# Next, we merge the channels in order to build a new image
img1 = cv2.merge([r, g, b])OpenCV:
Вывод:
Матплотлиб:
Вывод:
Итак, теперь для img1 matplotlib работает правильно, но для OpenCV мы получили инвертированные цвета. К счастью, нам легко визуально проверить, правильно ли отображаются цвета.
Обработка видео
Сначала давайте посмотрим, что такое видео. На самом деле это последовательность изображений, создающая видимость движения. Видео можно рассматривать как набор изображений (кадров). Для получения дополнительной информации перейдите по следующей ссылке.
При обработке видео мы также можем изменять и модифицировать его цвета. В следующем примере мы разделим каждый цветовой кадр на три цветовых канала. Они хранятся в виде матриц той же высоты и ширины, что и исходное видео. Затем, изменяя и модифицируя его значения, мы можем создать забавный визуальный эффект.
# Creating the VideoCapture object cap=cv2.VideoCapture("Video.mp4") ret, frame=cap.read()# Define the codec and create VideoWriter object fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') out = cv2.VideoWriter('output2.mp4', fourcc, 10, (640,360)) # Spliting our chanels (b, g, r)=cv2.split(frame) for i in range(100): # In every iteration increase a blue channel pixel value for 1. b = b+1 frame = cv2.merge([b, g ,r ] ) out.write(frame) out.release()
Как написать текст на картинке?
Написание текста на изображениях абсолютно необходимо для обработки изображений. Итак, давайте научимся это делать.
Во-первых, нам нужно несколько параметров. Во-вторых, нам нужно определить тип нашего шрифта. Как только мы это сделали, мы собираемся использовать функцию cv2.putText(). После добавления некоторых аргументов, таких как начальная точка (предоставляется звездочка текстовой строки в верхнем левом углу), размер, цвет и тип линии нашего текста, мы готовы к работе. Последний предоставленный параметр — это тип линии. В OpenCV есть три доступных типа строк (cv2.LINE_4, cv2.LINE_8, cv2.LINE_AA).
Теперь давайте немного развлечемся и попробуем воссоздать наш логотип Datahacker.rs.
# Creating our image img = np.zeros((400, 400, 3), dtype="uint8") img[:] = (255,255,255)# Creating "Datahacker" logo cv2.rectangle(img, (76,76), (324,300), (0,0,0), (2)) font=cv2.FONT_ITALIC font2=cv2.FONT_HERSHEY_PLAIN cv2.putText((img),"H A C K E R", (100,350), font, (1), (0,0,0), 2, cv2.LINE_AA) cv2.putText((img),"D", (120,162), font2, (5), (0,0,0), 5, cv2.LINE_AA) cv2.putText((img),"T", (120,264), font2, (5), (0,0,0), 5, cv2.LINE_AA) cv2.putText((img),"A", (240,164), font2, (5), (0,0,0), 5, cv2.LINE_AA) cv2.putText((img),"A", (240,264), font2, (5), (0,0,0), 5, cv2.LINE_AA)cv2_imshow(img)
Если мы хотим создать GIF из этого логотипа, мы будем использовать следующий код:
# Creating the images img = np.zeros((400, 400, 3), dtype="uint8") img[:] = (255,255,255) plt.imshow(img) cv2.rectangle(img, (76,76), (324,300), (0,0,0), (2)) font=cv2.FONT_ITALIC font2=cv2.FONT_HERSHEY_PLAIN cv2.putText((img),"D", (120,162), font2, (5), (0,0,0), 5, cv2.LINE_AA) plt.axis("off") # Ploting the image that we are created plt.imshow(img) # Saving an image that we are created # Dots per inch (dpi) is resolution that we chose plt.savefig("d_001.jpg", dpi = 800) cv2.putText((img),"A", (240,164), font2, (5), (0,0,0), 5, cv2.LINE_AA) plt.axis("off") plt.imshow(img) plt.savefig("d_002.jpg", dpi = 800) cv2.putText((img),"T", (120,264), font2, (5), (0,0,0), 5, cv2.LINE_AA) plt.axis("off") plt.imshow(img) plt.savefig("d_003.jpg", dpi = 800) cv2.putText((img),"A", (240,264), font2, (5), (0,0,0), 5, cv2.LINE_AA) plt.axis("off") plt.imshow(img) plt.savefig("d_004.jpg", dpi = 800) cv2.putText((img),"H A C ", (100,350), font, (1), (0,0,0), 2, cv2.LINE_AA) plt.axis("off") plt.imshow(img) plt.savefig("d_005.jpg", dpi = 800) cv2.putText((img),"H A C K E R", (100,350), font, (1), (0,0,0), 2, cv2.LINE_AA) plt.axis("off") plt.imshow(img) plt.savefig("d_006.jpg", dpi = 800)# This will load saved .jpg files and create a gif animation import os import imageio png_dir = '../content' images = [] for file_name in sorted(os.listdir(png_dir)): print(file_name) if file_name.endswith('.jpg'): file_path = os.path.join(png_dir, file_name) images.append(imageio.imread(file_path)) imageio.mimsave('../content/movie1.gif', images, fps = 1
Вывод:

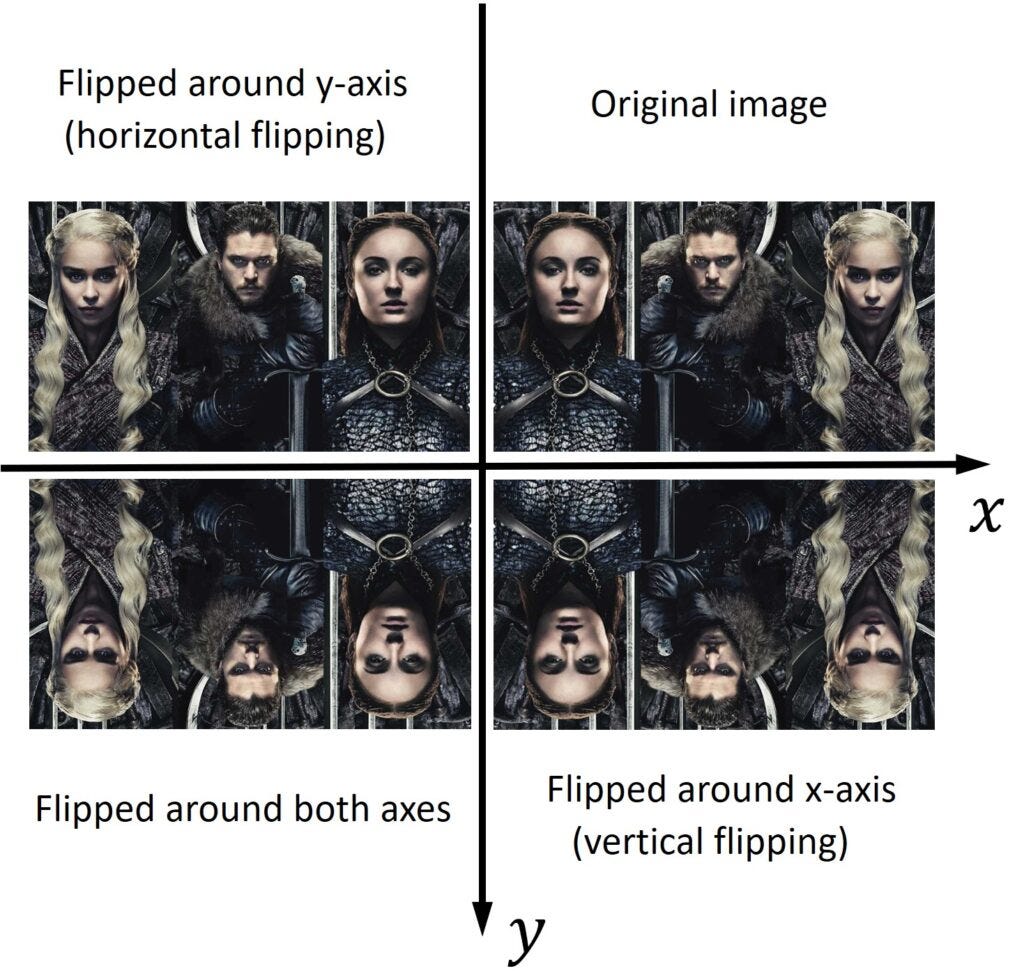
Как перевернуть изображение с помощью OpenCV?
Итак, мы узнали, как применять некоторые базовые операции в OpenCV, и теперь пришло время углубиться в наши первые методы обработки изображений. Эти методы являются фундаментальными инструментами практически для всех областей компьютерного зрения. В Open CV мы можем использовать преобразования, такие как изменение размера изображения, перевод изображения, поворот изображения и переворот изображения.
Давайте изучим один из них. Это преобразование называется флиппингом. Это означает, что мы собираемся отразить наше изображение вокруг оси x или y. Это очень просто. Нам просто нужно вызвать cv2.flip()function и предоставить только один аргумент. Этот аргумент является значением, которое будет определять, вокруг каких осей мы будем отражать наше изображение. Значение 1 указывает, что мы собираемся отразить наше изображение вокруг оси y (горизонтальное отражение). С другой стороны, значение 0 указывает, что мы собираемся отразить изображение вокруг оси x (вертикальное отражение). Если мы хотим перевернуть изображение вокруг обеих осей, мы будем использовать отрицательное значение (например, -1).
Матрица, которую мы используем для выполнения этой операции в линейной алгебре, называется матрицей отражения. Для операций переворачивания в Python эта матрица не требуется, но полезно знать, как она выглядит.

# Fliping the image around y-axis flipped = cv2.flip(img, 1) cv2_imshow(flipped)# Fliping the image around x-axis flipped = cv2.flip(img, 0) cv2_imshow(flipped)# Fliping the image around both axes flipped = cv2.flip(img, -1) cv2_imshow(flipped)
Как сделать фильтр сепия и тиснение
Когда мы хотим размыть или повысить резкость нашего изображения, нам нужно применить линейный фильтр. Существует несколько типов фильтров, которые мы часто используем при обработке изображений. В этом посте мы покажем, как создавать очень интересные эффекты фильтра, которые широко популярны в социальных сетях, особенно в Instagram.
Эффект сепии
Процесс создания эффекта сепии включает следующие шаги. Красный, зеленый и синий каналы перемножаются с определенными коэффициентами и создают новые значения для красного, зеленого и синего. Затем мы разделяем наши каналы. После их обработки мы получили новые каналы для красного, зеленого и синего. Как только это будет закончено, мы создадим наше окончательное выходное изображение, объединив каналы в новом красном, новом зеленом и новом синем. Наконец, мы наносим наше изображение и видим эффект сепии, который мы создали. Он напоминает старый коричневый пигмент, который широко использовался фотографами на заре фотографии.
# Splitting the channels
(b,g,r)=cv2.split(img1)
r_new = r*0.393 + g*0.769 + b*0.189
g_new = r*0.349 + g*0.686 + b*0.168
b_new = r*0.272 + g*0.534 + b*0.131
img_new=cv2.merge([b_new, g_new, r_new])
cv2_imshow(img_new)Вывод:

Эффект тиснения
Здесь мы проиллюстрируем еще один интересный эффект, называемый тиснением. Как только мы отфильтруем наше изображение, мы получим очень низкую разницу, а это означает, что выходное изображение будет довольно черным. Поэтому мы добавим константу 128 и получим результирующее изображение в сером цвете. Этот пример демонстрирует, как мы можем создать эффект тиснения.
# Creating our emboss filter
filter = np.array([[0,1,0],[0,0,0],[0,-1,0]])
# Applying cv2.filter2D function on our Logo image
emboss_img_1=cv2.filter2D(img2,-1,filter)
emboss_img_1=emboss_img_1+128
cv2_imshow(emboss_img_1)Вывод:

Морфологические преобразования
Когда мы хотим удалить шум на изображениях, мы можем использовать морфологические преобразования. Существуют две основные морфологические трансформации, которые называются дилатацией и эрозией. Они присутствуют при обработке изображений в разных приложениях. Как только мы изучим эти две основные морфологические операции, мы сможем комбинировать их для создания дополнительных операций, таких как открытие и закрытие.
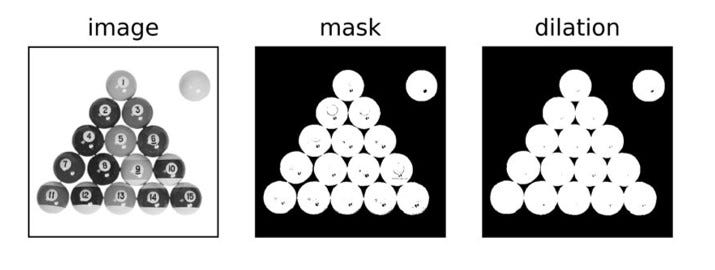
Дилатация - это именно то, на что это похоже. Это добавление (расширение) ярких пикселей объекта на данном изображении. Итак, как мы можем расширить или расширить изображение? Нам просто нужно выполнить свертку нашего входного изображения с ядром. Ядро определяется относительно точки привязки, которая обычно размещается в центральном пикселе.
На рисунке ниже у нас есть входное изображение (левое изображение) и ядро (среднее изображение). Мы собираемся взять наше ядро и запустить его по всему изображению, чтобы вычислить локальный максимум для каждой позиции ядра. Этот локальный максимум мы будем хранить в выходном изображении.

Итак, давайте посмотрим, как мы можем реализовать это в OpenCV. В качестве первого шага мы загрузим наше входное изображение, и нам нужно установить его порог, чтобы создать двоичное изображение. В этом посте вы можете найти подробное объяснение порогового значения. Также, если вам нравятся иллюстрации в этом посте, ознакомьтесь с книгой под названием Стостраничная книга Computer Vision OpenCV». Эта книга поможет вам очень быстро освоить компьютерное зрение.]

Стостраничная книга Computer Vision OpenCV
# Loading an input image and performing thresholding img = cv2.imread('Billiards balls 1.jpg', cv2.IMREAD_GRAYSCALE) _, mask=cv2.threshold(img, 230, 255, cv2.THRESH_BINARY_INV)# Creating a 3x3 kernel kernel=np.ones((3,3), np.uint8) # Performing dilation on the mask dilation=cv2.dilate(mask, kernel)# Plotting the images titles=["image","mask","dilation"] images=[img, mask, dilation]for i in range(3): plt.subplot(1, 3, i+1), plt.imshow(images[i], "gray") plt.title(titles[i]) plt.xticks([]),plt.yticks([]) plt.show[]
Вывод:
Как обнаружить лица в OpenCV?
Если у вас есть камера любого типа, которая выполняет обнаружение лиц, она, вероятно, использует каскадный классификатор на основе функций Хаара для обнаружения объектов. Теперь мы узнаем, что это за классификаторы каскада Хаара и как их использовать для распознавания лиц, глаз и улыбок.
Есть несколько проблем с распознаванием лиц, которые нам нужно решить. Мы часто имеем дело с изображением высокого разрешения, мы не знаем размер лица на изображении и не знаем, сколько лиц на изображении. Более того, нам нужно учитывать разные этнические или возрастные группы людей с бородой или людей в очках. Итак, когда дело доходит до распознавания лиц, очень сложно получить точные и быстрые результаты.
Но благодаря Виоле и Джонсу это больше не проблема. Они придумали каскад Хаара (алгоритм Виолы-Джонса) — алгоритм обнаружения объектов с помощью машинного обучения, который можно использовать для идентификации объектов на изображениях или видео. Он состоит из множества простых функций, называемых функциями Хаара, которые используются для определения того, присутствует ли объект (лицо, глаза) на изображении/видео или нет.

Теперь давайте посмотрим, как мы можем реализовать каскадные классификаторы Хаара с помощью Python.
Прежде чем приступить к программированию, обязательно скачайте следующие три файла из каталога GitHub Каскады Хаара и загрузите их в свой скрипт Python.
# Loading the image
img = cv2.imread("emily_clark.jpg")В следующих строках кода мы вызываем классификаторы face_cascade, eye_cascade и smile_ cascade.
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier("haarcascade_eye.xml")
smile_cascade = cv2.CascadeClassifier('haarcascade_smile.xml')Далее нам нужно преобразовать наше изображение в оттенки серого, потому что каскады Хаара работают только с серыми изображениями. Итак, мы собираемся детектировать лица, глаза и улыбки на изображениях в градациях серого, а на цветных изображениях будем рисовать прямоугольники вокруг обнаруженных лиц.
На первом этапе мы обнаружим лицо. Чтобы извлечь координаты прямоугольника, который мы собираемся нарисовать вокруг обнаруженного лица, нам нужно создать грани объекта. В этом объекте мы будем хранить наши обнаруженные лица. С помощью функции detectMultiScale() мы получим кортеж из четырех элементов: x и y — координаты левого верхнего угла, а w и h — ширина и высота прямоугольника. Этот метод требует несколько аргументов. Первое — это серое изображение, входное изображение, на котором мы будем обнаруживать лица. Второй аргумент — это коэффициент масштабирования, который говорит нам, насколько уменьшается размер изображения при каждом масштабе изображения. Третий и последний аргумент — это минимальное количество соседей. Этот параметр указывает, сколько соседей должен иметь каждый прямоугольник-кандидат, чтобы сохранить его.
# Creating an object faces
faces= face_cascade.detectMultiScale (gray, 1.1, 10)
# Drawing rectangle around the face
for(x , y, w, h) in faces:
cv2.rectangle(img, (x,y) ,(x+w, y+h), (0,255,0), 3)
cv2_imshow(img)Вывод:

Как определить ориентиры лица?
Обмен изображениями лиц — чрезвычайно популярный тренд в социальных сетях. Snapchat, Cupace, MSQRD, вероятно, являются наиболее широко используемыми приложениями с возможностью смены лица. За несколько секунд вы можете легко поменять свое лицо на лицо вашего друга или на некоторые забавные черты. Однако, хотя замена лица кажется очень простой, это непростая задача. Теперь вы можете задаться вопросом, «как эти приложения могут выполнять такую продвинутую замену лица»?
Чтобы выполнить замену лица, мы не можем просто обрезать одно лицо и заменить его другим. Что нам нужно сделать, так это локализовать ключевые точки, которые описывают уникальное расположение компонента лица на изображении (глаза, нос, брови, рот, линия челюсти и т. д.). Для этого нам нужно разработать метод прогнозирования формы, который идентифицирует важные структуры лица. В нашем коде мы собираемся реализовать метод, разработанный двумя шведскими исследователями компьютерного зрения Каземи и Салливаном в 2014 году, который называется Выравнивание лица за одну миллисекунду с ансамблем деревьев регрессии. Этот детектор очень быстро обнаруживает ориентиры лица и точно. Чтобы лучше понять этот метод, взгляните на следующее изображение.

На этом рисунке вы можете увидеть тренировочный набор из 68 помеченных точек лица с определенными координатами, которые окружают определенные части лица.
Для обнаружения лицевых ориентиров воспользуемся библиотекой dlib. Во-первых, мы обнаружим лицо на входном изображении. Затем мы будем использовать тот же метод для определения ориентиров лица.
# Necessary imports import cv2 import dlib import numpy as np from google.colab.patches import cv2_imshow# Loading the image and converting it to grayscale img= cv2.imread('Capture 8.PNG') gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Чтобы обнаружить лицо на нашем изображении, нам нужно вызвать фронтальный детектор лица dlib.get_frontal_face_detector()из библиотеки dlib.
# Initialize dlib's face detector
detector = dlib.get_frontal_face_detector()
# Detecting faces in the grayscale image
faces = detector(gray)Для обнаружения ориентиров лица воспользуемся аналогичным методом. Во-первых, мы загрузим предиктор лицевых ориентиров dlib.shape_predictor из библиотеки dlib. Кроме того, для этого метода предсказания формы нам нужно загрузить файл с именем "shape_predictor_68_face_landmarks.dat". Используя следующую команду, вы можете загрузить и разархивировать этот файл прямо в свой скрипт Python.
!wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2 !bunzip2 "shape_predictor_68_face_landmarks.dat.bz2"p = "shape_predictor_68_face_landmarks.dat" # Initialize dlib's shape predictor predictor = dlib.shape_predictor(p) # Get the shape using the predictor landmarks=predictor(gray, face)
Теперь давайте посмотрим, как мы можем извлечь координаты ориентиров лица из этого объекта.
for n in range(0,68):
x=landmarks.part(n).x
y=landmarks.part(n).y
cv2.circle(img, (x, y), 4, (0, 0, 255), -1)
cv2_imshow(img)Вывод:

Мы можем ясно видеть, что маленькие красные круги соответствуют определенным чертам лица на лице (глазам, носу, рту, бровям, линии подбородка).
Как выровнять лица с помощью OpenCV?
Выравнивание лица — это один из важных шагов, который нам нужно освоить, прежде чем мы начнем работать над некоторыми более сложными задачами обработки изображений в Python. Выравнивание лица может быть реализовано как процесс преобразования различных наборов точек с входных изображений (входных систем координат) в одну систему координат. Мы можем назвать эту систему координат выходной системой координат и определить ее как нашу стационарную систему отсчета. Наша цель — деформировать и преобразовать все входные координаты и выровнять их с выходными координатами. Для этого применим три основных аффинных преобразования: вращение, перемещение и масштабирование. Таким образом, мы можем преобразовать ориентиры лица из входной системы координат в выходную систему координат.
Для распознавания лиц и глаз мы будем использовать каскадные конфигурации OpenCV Haar (модули обнаружение лица и обнаружение глаз).
# Creating face_cascade and eye_cascade objects face_cascade=cv2.CascadeClassifier("haarcascade_frontalface_default.xml") eye_cascade=cv2.CascadeClassifier("haarcascade_eye.xml"# Loading the image img = cv2.imread('emily.jpg')# Converting the image into grayscale gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # Creating variable faces faces= face_cascade.detectMultiScale (gray, 1.1, 4) # Defining and drawing the rectangle around the face for(x , y, w, h) in faces: cv2.rectangle(img, (x,y) ,(x+w, y+h), (0,255,0), 3)
Теперь, когда у нас есть прямоугольник, мы готовы перейти к обнаружению глаз. Для этого нам сначала нужно создать две области интереса, которые будут располагаться внутри прямоугольника. Нам нужна первая область для изображения в градациях серого, где мы собираемся обнаружить глаза. Вторая область потребуется для цветного изображения, где мы будем рисовать прямоугольники.
# Creating two regions of interest
roi_gray=gray[y:(y+h), x:(x+w)]
roi_color=img[y:(y+h), x:(x+w)]Далее мы обнаружим глаза с помощью метода, аналогичного описанному выше.
# Creating variable eyes
eyes = eye_cascade.detectMultiScale(roi_gray, 1.1, 4)
index=0
# Creating for loop in order to divide one eye from another
for (ex , ey, ew, eh) in eyes:
if index == 0:
eye_1 = (ex, ey, ew, eh)
elif index == 1:
eye_2 = (ex, ey, ew, eh)
# Drawing rectangles around the eyes
cv2.rectangle(roi_color, (ex,ey) ,(ex+ew, ey+eh), (0,0,255), 3)
index = index + 1Теперь давайте нарисуем линию между центральными точками двух глаз. Но прежде чем мы это сделаем, нам нужно вычислить координаты центральных точек прямоугольников. Для лучшей визуализации взгляните на следующий пример.
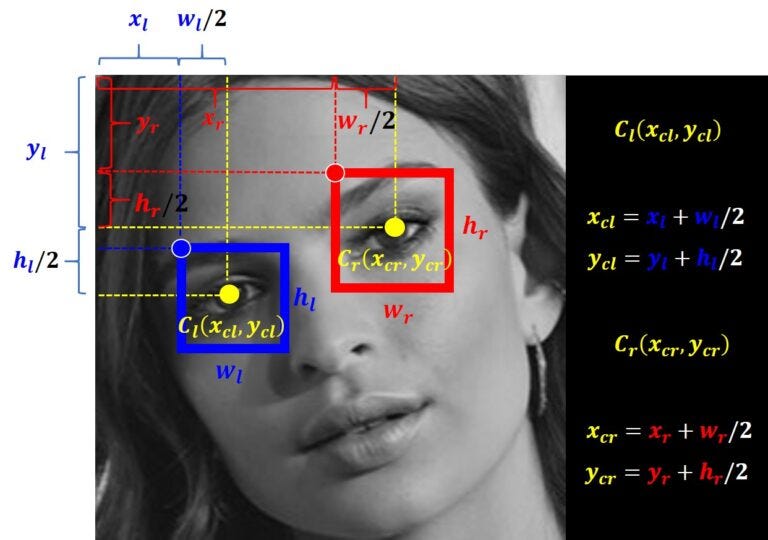
Теперь давайте реализуем эти вычисления в нашем коде. Обратите внимание, что индекс 0 относится к координате x, индекс 1 относится к координате y, индекс 2 относится к ширине прямоугольника и, наконец, индекс 3 относится к высоте прямоугольника.
# Calculating coordinates of a central points of the rectangles
left_eye_center = (int(left_eye[0] + (left_eye[2] / 2)), int(left_eye[1] + (left_eye[3] / 2)))
left_eye_x = left_eye_center[0]
left_eye_y = left_eye_center[1]
right_eye_center = (int(right_eye[0] + (right_eye[2]/2)), int(right_eye[1] + (right_eye[3]/2)))
right_eye_x = right_eye_center[0]
right_eye_y = right_eye_center[1]
cv2.circle(roi_color, left_eye_center, 5, (255, 0, 0) , -1)
cv2.circle(roi_color, right_eye_center, 5, (255, 0, 0) , -1)
cv2.line(roi_color,right_eye_center, left_eye_center,(0,200,200),3)Следующим шагом будет проведение горизонтальной линии и вычисление угла между этой линией и линией, соединяющей две центральные точки глаз. Наша цель — повернуть изображение на этот угол. Мы можем сделать это следующим образом.
if left_eye_y > right_eye_y: A = (right_eye_x, left_eye_y) # Integer -1 indicates that the image will rotate in the clockwise direction direction = -1 else: A = (left_eye_x, right_eye_y) # Integer 1 indicates that image will rotate in the counter clockwise # direction direction = 1cv2.circle(roi_color, A, 5, (255, 0, 0) , -1) cv2.line(roi_color,right_eye_center, left_eye_center,(0,200,200),3) cv2.line(roi_color,left_eye_center, A,(0,200,200),3) cv2.line(roi_color,right_eye_center, A,(0,200,200),3)
Чтобы вычислить угол, нам сначала нужно найти длину двух катетов прямоугольного треугольника. Тогда мы можем найти искомый угол, используя следующую формулу.
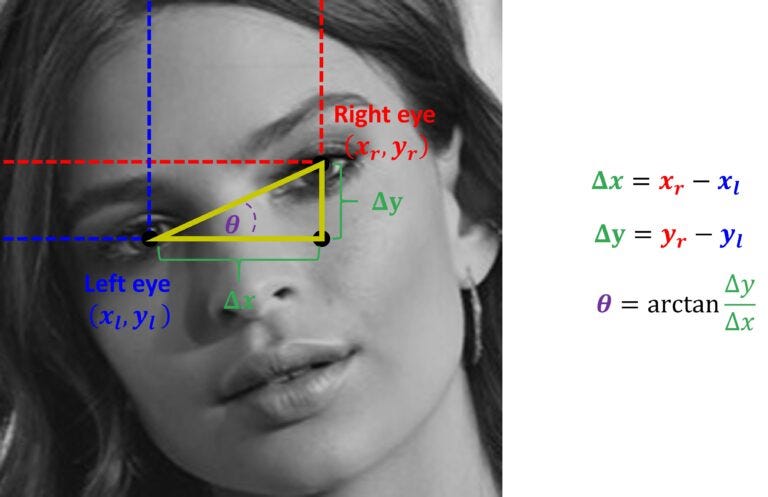
delta_x = right_eye_x - left_eye_x
delta_y = right_eye_y - left_eye_y
angle=np.arctan(delta_y/delta_x)
angle = (angle * 180) / np.piТеперь мы можем, наконец, повернуть наше изображение на угол θ.
# Width and height of the image
h, w = img.shape[:2]
# Calculating a center point of the image
# Integer division "//"" ensures that we receive whole numbers
center = (w // 2, h // 2)
# Defining a matrix M and calling
# cv2.getRotationMatrix2D method
M = cv2.getRotationMatrix2D(center, (angle), 1.0)
# Applying the rotation to our image using the
# cv2.warpAffine method
rotated = cv2.warpAffine(img, M, (w, h))
cv2_imshow(rotated)Вывод:

Теперь нам нужно масштабировать наше изображение, для чего мы будем использовать расстояние между глазами на этом изображении в качестве опорного кадра. Но сначала нам нужно рассчитать это расстояние. Мы уже вычислили длину двух сторон в прямоугольном треугольнике. Итак, мы можем использовать теорему Пифагора для вычисления расстояния между глазами, поскольку оно представляет собой гипотенузу. Мы можем сделать то же самое со всеми другими изображениями, которые мы обрабатываем с помощью этого кода. После этого мы можем рассчитать соотношение этих результатов. и масштабируем наши изображения на основе этого соотношения.
c = np.sqrt((delta_x * delta_x) + (delta_y * delta_y)) c_1 = np.sqrt((delta_x_1 * delta_x_1) + (delta_y_1 * delta_y_1)) ratio = c / c_1# Defining the width and height h=476 w=488 # Defining aspect ratio of a resized image dim = (int(w * ratio), int(h * ratio)) # We have obtained a new image that we call resized3 resized = cv2.resize(rotated, dim)# Defining the width and height h=740 w=723 # Defining aspect ratio of a resized image dim = (int(w * ratio), int(h * ratio)) # We have obtained a new image that we call resized3 resized = cv2.resize(rotated, dim) cv2_imshow(resized)
Вывод:


Как видите, мы получили отличные результаты.
Резюме
Прочитав этот пост, вы получили базовые знания, которые помогут вам в более сложной задаче обработки изображений. Если вы хотите изучить компьютерное зрение с полным пониманием сложного кода и математических формул, ознакомьтесь с этой книгой, которая даст вам все ответы, которые вам нужны.